Scrape the internet
declaratively
We use LLMs to automatically build self-healing web scrapers that extract exactly the data you need.
How does Sonata work?
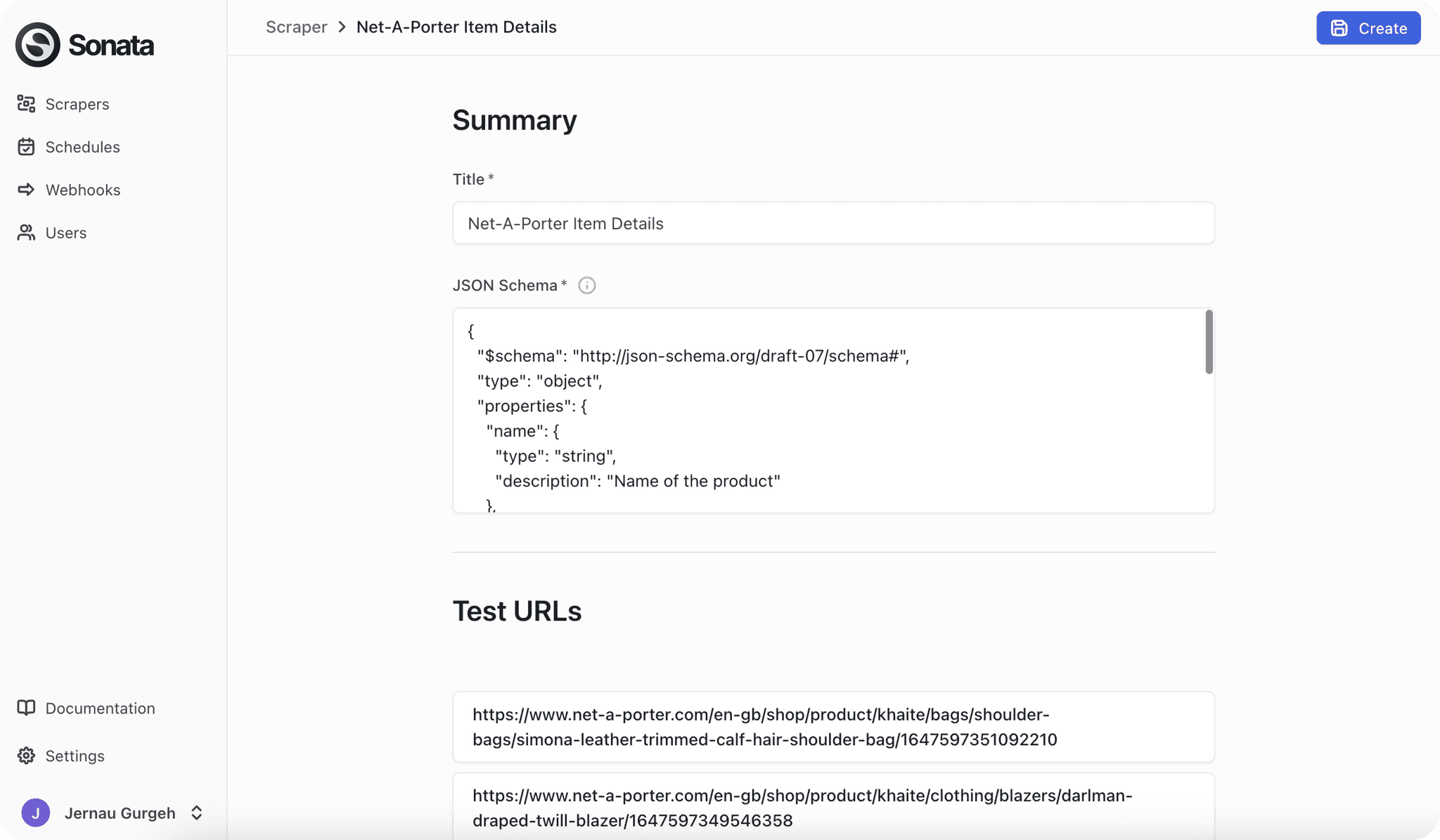
1. Set up a scraper
To get started, all you need is a JSON schema that describes the data you want to extract and a list of URLs.
You can create scrapers from our UI, through our Python or TypeScript clients, or by using our API.
2. Sonata compiles a scraper
Using the JSON schema and the URLs, Sonata figures out how to extract the right data.
This can take a few minutes while the LLM works through the structure.
3. Use the compiled scraper
Once the scraper is compiled, you can run it on any similar webpage.
You can run the scrapers on a schedule, or on-demand. The data can be sent to any webhook or API. We handle proxies and other infrastructure for you.
Because the LLM has already compiled, this is much faster - i.e. the performance is the same as a scraper you might write by hand.
4. Sonata scrapers self-heal
If the scraper fails to find the data on a subsequent run it’ll self-heal by updating its internal code, and explain to you what went wrong.
No more maintenance, no more annoying broken scrapers, no more wasted time.